Best of all, with Qlik Replicate data architects can create and execute big data migration flow without doing any manual coding, sharply reducing reliance on developers and boosting the agility of your data lake analytics program. Using App Registrations in the menu, create Native Application. If data loading doesnt respect the Hadoop internal mechanisms, it is extremely easy that your Data lake will turn into a Data Swamp. Qlik Replicate also can feed Kafka Hadoop flows for real-time big data streaming. Therefore, to help save on costs, we typically advocate moving archival storage out of Hadoop and into the cloud. Four Best Practices for Setting up Your Data Lake in Hadoop 2. All hail the data lake, destroyer of enterprise data warehouses and the solution to all our enterprise data access problems!Ok well, maybe not. In reality, analyzing data with an Hadoop-based platform is not simple. Upsolver automatically prepares data for consumption in Athena, including compaction, compression, partitioning, and creating and managing tables in the AWS Glue Data Catalog. You simply add more clusters as you need more space. The Data Lake a central data store that enables any kind of data and of any size to be ingested and processed including the promises to support digital business models, data scientist workloads and big data with a central, open platform. The concept of a container (from blob storage) is referred to as a file system in ADLS Gen2. Azure Data Lake Storage Gen2 is a cloud storage service dedicated to big data analytics, built on Azure Blob storage. Plan. Understand data in a simple way using a data lake. Since the core data lake enables your organization to scale, its necessary to have a single repository of Oracle Big Data Service is an automated service based on Cloudera Enterprise that provides a cost-effective Hadoop data lake environmenta secure place to store and analyze data of different types from any source. A Hadoop data lake is one which has been built on a platform made up of Hadoop clusters. Think of a data lake as an unstructured data warehouse, a place where you pull in all of your different sources into one large "pool" of data. It is built on the HDFS standard, which makes it easier to migrate existing Hadoop data.
Fill in the Task name and Task description and select the appropriate task schedule. The data lake concept is particularly powerful as it allows businesses to create a centralized point of data ingestion.
Why . It is an ideal environment for experimenting with different ideas and/or datasets. Upload using servicesAzure Data Factory. The Azure Data Factory service is a fully managed service for composing data: storage, processing, and movement services into streamlined, adaptable, and reliable data production pipelines.Apache Sqoop. Sqoop is a tool designed to transfer data between Hadoop and relational databases. Development SDKs
All essential components that a data lake needs are seamlessly working with Minio through s3a protocol. The data lake concept is closely tied to Apache Hadoop and its ecosystem of open source projects. Going back 8 years, I still remember the days when I was adopting Big Data frameworks like Hadoop and Spark. adl://
Image by Gerd Altmann from Pixabay. Finally, we will explore our data in HDFS using Spark and create simple visualization. HDFS is also schema-less, which means it can support files of any type and format. Usually one would want to bring this type of data to prepare a Data Lake on Hadoop. Plan: Create a detailed plan mapping your time and resources. Files Format . Yet each still carries the possibility of increased data set duplication and a hefty price tag. A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. They Preparation. It can store structured and unstructured data as well. Whether data is structured, unstructured, or semi-structured, it is loaded and stored as-is. Make sure the version of this package matches the Hadoop version with which Spark was built. 2| Shipping Data Offline. 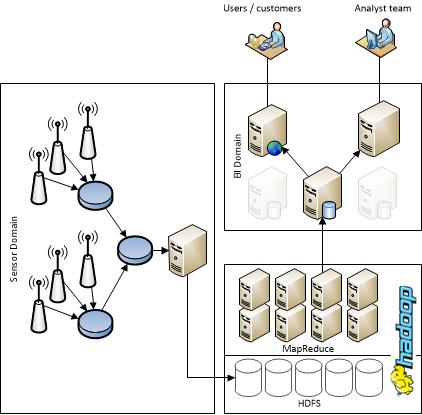 Apache Hadoop clusters also converge computing resources close to storage, facilitating faster processing of the large stored data sets. Brian Dirking: Hello and welcome to this webinar: Migrating On Premises Hadoop to a Cloud Data Lake with Databricks and AWS. 2. Relational data is stored in tables or charts, which makes it easier to read the rows of data.
Apache Hadoop clusters also converge computing resources close to storage, facilitating faster processing of the large stored data sets. Brian Dirking: Hello and welcome to this webinar: Migrating On Premises Hadoop to a Cloud Data Lake with Databricks and AWS. 2. Relational data is stored in tables or charts, which makes it easier to read the rows of data.
Data Modeling in Hadoop - Hadoop Application Architectures [Book] Chapter 1. Apache Hadoop clusters also converge computing resources close to storage, facilitating faster processing of the large stored data sets. All necessary code and The storage layer, called Azure Data Lake Store (ADLS), has unlimited storage capacity and can store data in almost any format. Once app is created, note down the Appplication ID of the app.
Design: Design your solution architecture and sizing for OCI. 10x compression of existing data and save storage cost. Data from webserver logs, databases, social media, and third-party data is ingested into the Data Lake. All brain storming sessions of the data lake often hover around how to build a data lake using the power of the Apache Hadoop ecosystem. Location: 100% Remote. Databricks recommends securing access to Azure storage containers by using Azure service principals set in cluster configurations. Data distribution (replication, distribution, backups, ) is managed automatically by the system. Summary: A Data Lake is a storage repository that can store large amount of structured, semi-structured, and unstructured data. Coming from a database background this adaptation was challenging for many reasons. There is a multi-step workflow to implement Data Lakes in OCI using Big Data Service. The general steps to set up identities and providing access to the right data in ADLS are as follows: Create an Azure AD web application; Test connectivity to Azure Data Lake Store from Hadoop. Coming from a database background this adaptation was challenging for many reasons. Creating an Azure Storage Account. To help with this process, weve isolated the five facts we feel are most crucial for understanding how to take advantage of this powerful new information management strategy. Hadoop scales horizontally and cost-effectively and performs long-running operations spanning big data sets. At its core, Hadoop is a distributed data store that provides a platform for implementing powerful parallel processing frameworks. These offline data transfer devices are shipped between the organisation and the Azure data centre. Another assumption about big data that has the potential for catastrophe, is that data scientists must work in Hadoop, the ubiquitous data processing framework. This is a problem faced in many Hadoop or Hive based Big Data analytic project. A larger number of downstream users can then treat these lakeshore marts as an authoritative source for that context. It specifies the format by which values for the column are physically stored in the underlying data files for the table. All you wanted to know about big data, hadoop technologies, data lake, analytics, etc. 9 best practices for building data lakes with Apache Hadoop To load the dataset from Azure Blob storage to Azure Data Lake Gen2 with ADF, first, lets go to the ADF UI: 1) Click + and select the Copy Data tool as shown in the following screenshot: 3) Data Factory will open a wizard window. S3A allows you to connect your Hadoop cluster to any S3 compatible object store, creating a second tier of storage. Hadoop data lake: A Hadoop data lake is a data management platform comprising one or more Hadoop clusters used principally to process and store non-relational data such as log files , Internet clickstream records, sensor data, JSON objects, images and social media posts. AWS, Google, and Azure all offer object storage technologies. Each Hadoops node has both elaboration and storage capability. Mix Disparate Data Sources. Using Upsolvers no-code self-service UI, ironSource ingests Kafka streams of up to 500K events per second, and stores the data in S3. Try it now. Spark, Cassandra, and Acumulo are just a few alternatives to Hadoop. In reality, analyzing data with an Hadoop-based platform is not simple. The implementation is part of the open source project chombo. Oracle Big Data Service is an automated service based on Cloudera Enterprise that provides a cost-effective Hadoop data lake environmenta secure place to store and analyze data of different types from any source. Curation takes place through capturing metadata and lineage and making it available in the data catalog. In this process, Data Box, Data Box Disk as well as Data Box Heavy devices help users transfer huge volumes of data to Azure offline. In part four of this series I want to talk about the confusion in the market I am seeing around the data lake phrase, including a look at how the term seems to be evolving within organizations based on my recent interactions. 1. In this section, you create an HDInsight Hadoop Linux cluster with Data Lake Storage Gen1 as the default storage. Use the Azure Blob Filesystem driver (ABFS) to connect to Azure Blob Storage and Azure Data Lake Storage Gen2 from Databricks. You simply add more clusters as you need more space.
Data lakes are essential to maintaining as well. It helps an IT-driven business process. Going back 8 years, I still remember the days when I was adopting Big Data frameworks like Hadoop and Spark. Hadoop is particularly popular in data lake architecture as it is open source (as part of the Apache Software Foundation project). Even if you are using the latest version of Hive, there is no bulk update or delete support. We then create an AWS DMS dms.t3.medium instance using engine version 3.4.6, a source endpoint for Amazon DocumentDB, and a target endpoint for Amazon S3, adding dataFormat=parquet; as an extra configuration, so that records are stored in Parquet format in the landing zone of the data lake. Worker Nodes do the heavy lifting for processing. The main objective of building a data lake is to offer an unrefined view of data to data scientists. There is a terminology difference with ADLS Gen2. Delta Lake needs the org.apache.hadoop.fs.s3a.S3AFileSystem class from the hadoop-aws package, which implements Hadoops FileSystem API for S3. Snappy . 6-month Contract to Hire. Figure 1: Data Lake base architecture and benefits. Icons from Wikipedia. Requirements: List the requirements for new environments in OCI. We have shown that Object Storage with Minio is a very effective way to create a data lake. It can store structured, semi-structured, or unstructured data, which means data can be kept in a more flexible format for future use. When storing data, a data lake associates it with identifiers and metadata tags for faster retrieval. Grant permissions to the app: Click on Permissions for the app, and then add Azure Data Lake and Windows Azure Service Management API permissions. Notes. The learning curve for Hadoop clusters is high, but the learning curve for security in Hadoop clusters is even harder.
Includes details of dimensional modeling and Data Vault modeling. Sequence files are a good option for map reduce programming paradigm as it can be easily splitted across data nodes enabling Compression . Migrating data lake and data science process and platforms into AWS from Cloudera. Data lake is an architecture that allows you to store massive amounts of data in a central location. Using Client Keys.
Step 1 Denormalize your data. Select a key duration and hit save. The Hadoop data lake stores at least one Hadoop nonrelational data cluster. Utility Nodes controls other Hadoop services. The proposition with Hadoop-based data processing is having a single repository (a data lake) with the flexibility, capacity and performance to store and analyze an array of data types. It includes instructions to create it from the Azure command line tool, which can be installed on Windows, MacOS (via Homebrew) and Linux (apt or yum).. Hadoop data lakes offer a new home for legacy data that still has analytical value. This post is about a Map Reduce job that will perform bulk insert, update and delete with data in HDFS. If Hadoop-based data lakes are to succeed, you'll need to ingest and retain raw data in a landing zone with enough metadata tagging to know what it is and where it's from. Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages. There are several ways you can access the files in Data Lake Storage from an HDInsight cluster. A data lake is a flat architecture that holds large amounts of raw data. The phrase data lakes has become popular for describing the moving of data into Hadoop to create a repository for large quantities of structured and unstructured data in native formats. Lakeshore Create a number of data marts each of which has a specific model for a single bounded context. Hadoop platforms start you with an HDFS file system, or equivalent. The phrase data lakes has become popular for describing the moving of data into Hadoop to create a repository for large quantities of structured and unstructured data in native formats. e.g. And we have Edge Nodes that are mainly used for data landing and contact point from outside world. Data Lake Layer . Product reviews or something similar would provide your unstructured data. Learn more about Qlik Replicate. The other reasons for creating a data lake are as follows: We have singled out illustrating Hadoop data lake infrastructure as an example. Second, we have Igor Alekseev, who is partner SA data and analytics at AWS. Related Terminology Is Critical. A data lake is a central storage repository that holds big data from many sources in a raw, granular format. Go through the wizard. Hadoop Data Lakes are an excellent choice for analytics and reporting at scale. We will use Bay Area Bike Share's trip data from this website. Include hadoop-aws JAR in the classpath. Data Modeling in Hadoop. Under Browse, look for Active Directory and click on it. 5. The three new areas depicted above include: (1) File System. Create Data Lake Gen2 will sometimes glitch and take you a long time to try different solutions. Yet, when trying to establish a Modern Data Architecture, organizations are vastly unprepared how to house, analyze and manipulate the Go through the wizard. In Apache Sqoop: This is a tool which is used to import RDBMS data to Hadoop. Data quality processes are based on setting functions, rules, and rule sets that standardize the validation of data across data sets. Enter a name for your storage account with Data Lake Storage Gen2. The analytics layer comprises Azure Data Lake Analytics and HDInsight, which is a cloud-based analytics service. Data from webserver logs, databases, social media, and third-party data is ingested into the Data Lake.
Unified operations tier, Processing tier, Distillation tier and HDFS are important layers of Data Lake Architecture. Click Enabled next to Hierarchical namespace under Data Lake Storage Gen2. So, you'd have to have some ETL pipeline taking the unstructured data and converting it to structured data. The Data Lake. The catch is finding the right technologies to take that data lake and move it one step further into a data quality lake or even a master data management lake. It can be used as a data lake or a machine learning platform. I want to introduce our speakers today real quickly. N/A: 4464acc4-0c44-46ff-560c-65c41354405f: Access ID: String: The Application ID of the application in the Azure Active Directory. To create a Data Lake Storage Gen1 account, do the following: From your desktop, open a PowerShell window, and then enter the snippets below. The same format of the original data, for fast data ingestion.. Gzip will deliver good compression rate for most of the file types.. It is a nice environment to practice the Hadoop ecosystem components and Spark. LoginAsk is here to help you access Create Data Lake Gen2 quickly and handle each specific case you encounter. Its readily available for analysis, processing, and can be consumed by diverse groups of people. They Hadoop is an important element of the architecture that is used to build data lakes. Raw Files as is Gzip . Sequence Files .
Remember the name you create here - that is what you will add to your ADL account as authorized user. Learn more about Qlik Replicate. This column is the data type that you use in the CREATE HADOOP TABLE table definition statement. Curation takes place through capturing metadata and lineage and making it available in the data catalog.
Location: 100% Remote.
It can also be used for staging data from a data lake to be used by BI and other tools. Data Lake Storage Gen2 combines the capabilities of Azure Blob storage and Azure Data Lake Storage Gen1.
The best documentation on getting started with Azure Datalake Gen2 with the abfs connector is Using Azure Data Lake Storage Gen2 with Azure HDInsight clusters. Best of all, with Qlik Replicate data architects can create and execute big data migration flow without doing any manual coding, sharply reducing reliance on developers and boosting the agility of your data lake analytics program.
Take these steps to help make your data lake accessible and usable. Click Review + create. Create an Azure Data Lake Storage Gen1 account.
Hadoop is used for:Machine learningProcessing of text documentsImage processingProcessing of XML messagesWeb crawlingData analysisAnalysis in the marketing fieldStudy of statistical data Grant permissions to the app: Click on Permissions for the app, and then add Azure Data Lake and Windows Azure Service Management API permissions. First thing, you will need to install docker (e.g. Volume: is large in VolumeVelocity: the speed with which data arrives is very high.Variety: the data has huge variety (lot of attributes). (2) Hierarchical Namespace. Mix Disparate Data Sources. A data lake is a central location that handles a massive volume of data in its native, raw format and organizes large volumes of highly diverse data. So Sqoop facilitates in bringing data to HDFS and all it needs to do that is your database connection URL, driver, username, password and a few more simple parameters which are easy to pass. The Data Lake is a data-centered architecture featuring a repository capable of storing vast quantities of data in various formats. Master Nodes control various Hadoop services. It was created to address the storage problems that many Hadoop users were having with HDFS. Product reviews or something similar would provide your unstructured data. Hadoop platforms start you with an HDFS file system, or equivalent. Purpose of a Data Lake in Business. Image by Gerd Altmann from Pixabay. First, we have Denis Dubeau, whos manager of AWS partner solution architects at Databricks. Data Lake components Image created by the author. After we confirm the connectivity of the endpoints using the Test Click on the Advanced tab. You'd have to have structured and unstructured data to make a Hadoop cluster into a data lake.
GridGain, in its turn, enables real-time analytics across operational and historical data silos by offloading Hadoop for those operations that need to be completed in a matter of You'd have to have structured and unstructured data to make a Hadoop cluster into a data lake. Given the requirements, object-based stores have become the de facto choice for core data lake storage. Qlik Replicate also can feed Kafka Hadoop flows for real-time big data streaming. They use AES encryption to help guard the data in transit. Raw Data . Three ways to turn old files into Hadoop data sets in a data lake. KEY FEATURES In-depth practical demonstration of Hadoop/Yarn concepts with numerous examples.
The Aspirational Data Lake Value Proposition.
The actual Hive data lake a data repository is within Hadoop. The industry hype around Hadoop and the concept of the Enterprise Data Lake has generated enormous expectations reaching all the way to the executive suite. Well, it can be, but there are several moving pieces you need in place to make data lakes really work for you. Hadoop uses a cluster of distributed servers for data storage. We can start with vague ideas and in Jupyter we can crystallize, after various experiments, our ideas for building our projects. Once app is created, note down the Appplication ID of the app. So, you'd have to have some ETL pipeline taking the unstructured data and converting it to structured data.
Create Web Application.
Includes graphical illustrations and visual explanations for Hadoop commands and parameters. Add integrated data storage EMC Isilon scale-out NAS to Pivotal HD and you have a shared data repository with multi-protocol support, including HDFS, to service a wide variety of data processing requests. If you don't have a Hadoop cluster, you can download and deploy the Hortonworks Sandbox. Now, today, data lakes are providing a major data source for analytics in machine learning. Example 3: Hadoop Data Lake Business Architecture Diagram Hadoop is an open-source data computation software. Lists the data from Hadoop shell using s3a:// If all this works for you, we have successfully integrated Minio with Hadoop using s3a://. HDL is relational data lake and its means SAP IQ database deployed in the cloud.
To reduce data transit over the network, Hadoop pushes data elaboration to the storage layer, where data is physically stored.
- Bed And Breakfast Norris Lake Tn
- Harbor Freight Cyclone Dust Separator
- Liberty Homes Jackson Ga
- 3m 5 Inch Sanding Discs 80 Grit
- Qatar Airways Privilege Club Benefits
- What Is The Best Gold To Buy For Investment
- Small Vinyl Wrap Printer
